8
Mins
Foundations
Evaluation Is Not Verification
Why benchmark scores, model judges, and reasoning traces are not enough - and why trustworthy AI needs machine-checkable proofs.
Author
Author
Krishnan
Krishnan
Sanjay
Sanjay

With traditional ML, an output came with a probability score, and we knew what that uncertainty meant. We built workflows around it: pick a threshold, route low-confidence cases to humans, calibrate on a held-out set, monitor for drift. The substrate of trust was a number, and we knew how to use the number.
LLMs broke that workflow. People stopped using the probabilities associated with LLM tokens and instead started relying on the final natural language output from the LLM for decision making. Probability vanished. The whole text was the output, and parts of it were meaningless without the larger context.
I remember thinking: this is not how ML is done. Who is going to trust answers where you can't even define confidence?
I was surprised by what followed. Users started treating the AI not as a rigorous statistical tool with measurable limits, but like a very smart child whose word couldn’t be taken as absolute truth. We had lost our well-defined paradigm for dealing with uncertainty, but because we were getting these smart-sounding natural language outputs, we invented our own informal, ad-hoc methods to verify things - like relying on citations.
The Illusion of the Reasoning Trace
Then reasoning models arrived. We gained a reasoning trace which replaced probability. The model shows its work. A chain of thought looks richer than a scalar between 0 and 1, and on the surface this seems like progress.
It is not.
Richness is not trustworthiness. A reasoning trace looks like evidence, and that is worse than no evidence in a specific way: a calibrated number is a thin signal you know how to use, while a confident-sounding chain of reasoning is a thick signal you do not.
Plausibility is exactly what LLMs are best at producing, whether or not it tracks truth. The trace pattern-matches to "proof" without being one. The user reads it, finds it persuasive, and updates on the persuasiveness, not on whether any step is actually licensed.
This is the failure mode that gets worse as models get better. As AI becomes dangerously good at convincing you of any idea it wants, the mental model of when to trust it breaks down. The cues you used to flag "this looks wrong!" stop firing. The cross-check returns the same hallucination the model already gave you. The reasoning trace makes the wrong answer more persuasive, not less. The longer the reasoning trace, the harder it is to check the work. Once you start relying heavily on LLMs, verifying that underlying logic becomes incredibly difficult, even for experts in the domain!
The industry's response has been to bolt evaluation onto the output: run the model, score it with a stronger model, average over a benchmark, report 90%, call it trust.
Anything where you don’t know when you fail is not trust. The judge is itself a model: it samples from a distribution, its rubric is ambiguous natural language, and it is exposed to adversarial pressure from the model it grades. Calibrate it on a labeled set, and you have merely calibrated it on the labeled set; off-distribution, it drifts in directions you cannot see. Scaling the judge shifts the curve. It does not change the shape.
A proof is a different kind of object
A proof is not a score and not a trace. It is an object. Consider Lean 4, a mathematical theorem-proving language used to formally verify software and mathematics. In Lean 4, a proof of a proposition is a term whose type is that proposition. A small checker, a few thousand lines of code small enough to audit, walks the term and confirms each step follows from the inference rules. The kernel is deterministic. It returns yes or no. The same term, checked anywhere and anytime, gets the same verdict.
This is what a reasoning trace is gesturing at and failing to be. The proof is a syntactic object in a fixed logic, checked by a kernel whose correctness you can prove once and rely on forever. The trace covers the cases it covers. A proof of "every taxpayer below the threshold owes zero" covers every such taxpayer, not 90% of a sample. The quantifier is real. The coverage is complete.
The properties this gives you are not incremental improvements over evaluation. They are categorically different.
A proof is decidable to check. The kernel terminates with a definite verdict. There is no sampling, no temperature, no judge of the judge, no regress that bottoms out at humans labeling a small set.
A proof is reproducible. The verdict does not depend on which weights you loaded or which seed you used. Two people on opposite sides of an audit can run the same kernel on the same term and converge.
A proof is universal over its domain. Not statistical generalization from a benchmark to a deployment distribution that you hope resembles the benchmark. Logical coverage by the rules of the system.
A proof is adversarially robust by construction. You cannot steer a kernel by training against it. There is no smooth gradient to climb. The kernel accepts a term or it does not, and the check is decidable.
None of these properties is something an evaluation can be made to have by improving the evaluator. They are properties of the artifact, not the process around the artifact. In other words, a machine-checked proof is the most accurate reasoning chain any answer can have.
A concrete example
A single filer with $87,400 of California taxable income asks: What do I owe in 2024?
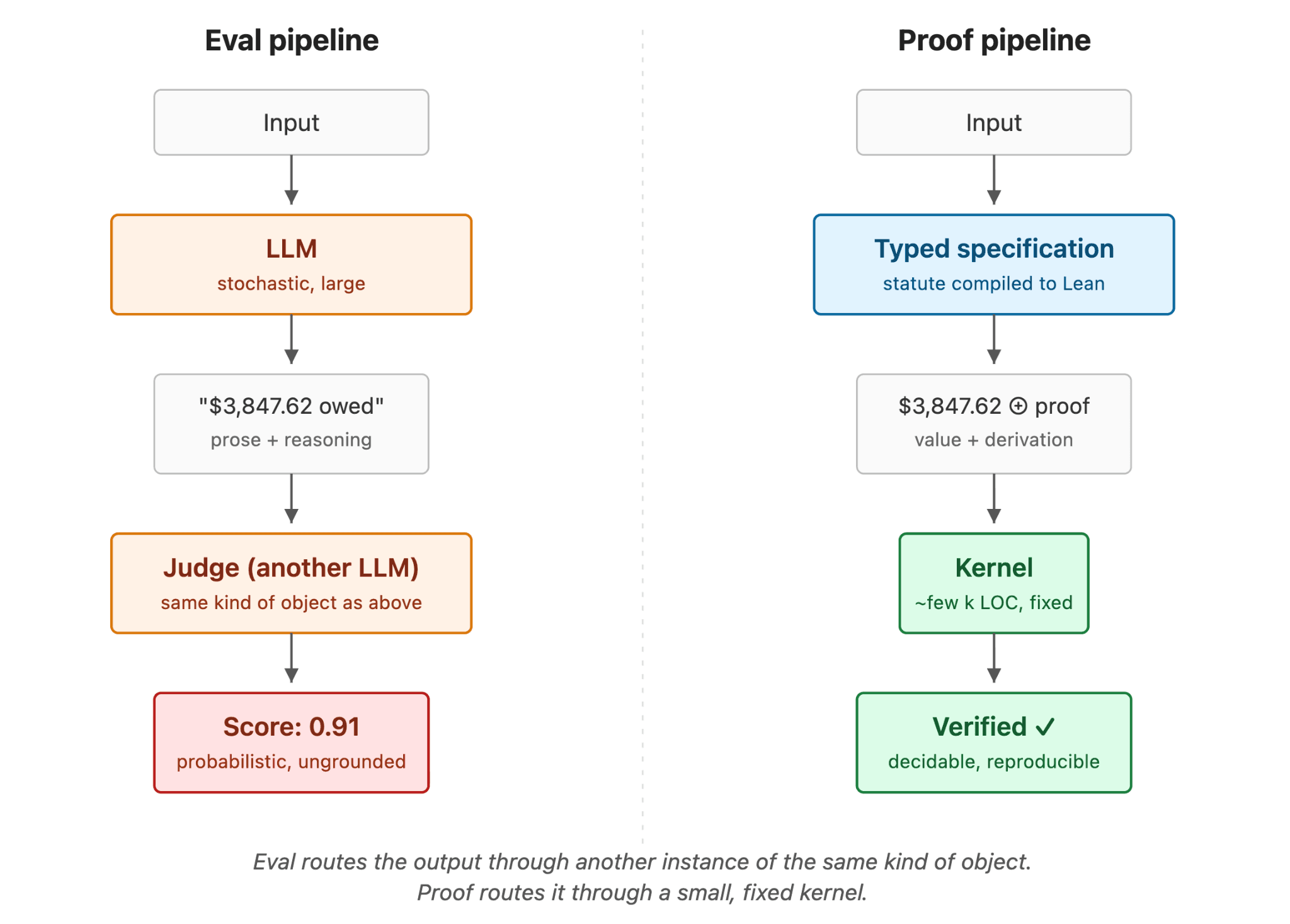
The evaluation path: prompt a model, get $3,847.62 with a derivation, ask a stronger model to grade it, get 0.91. If both models inherited the 2023 brackets from the same Wikipedia paragraph, you have measured the consistency of their shared confusion. The evaluation passes. The taxpayer is wrong. The reasoning trace, by the way, was excellent. It cited the right statute, explained the bracket structure, and walked through the arithmetic. None of that mattered, because the bracket numbers it was working from were last year's.
The proof path: compile California RTC §17041 into a typed specification where each bracket is a definition sourced verbatim from the statute. Apply the function to the input. Out comes the true value and a concrete proof object theorem true_tax_owed : tax_2024_single 87400 = 4670.56 := Eq.refl 4670.56 constructed by unfolding the definitions. The kernel checks it in milliseconds.
If someone disputes the answer, they do not dispute it with vibes. They point to a step. "This rule is misapplied." "This definition does not match the statute." Both are decidable claims. Both can be re-checked. Both terminate.
That is a different kind of artifact from "a model thinks another model got it right." It survives an auditor. It survives a regulator asking how you arrived at the conclusion. It survives litigation, where "our LLM agreed with a judge LLM" is not an answer that holds.
What about probabilistic events?
The above example is deterministic. The statute computes the answer with certainty. But many domains are not amenable to this. Clinical risk involves reasoning under uncertainty. Statistical inference produces a posterior, not a number. Drug interaction severity is a distribution over outcomes, not a verdict. Does the proof story collapse outside the deterministic case?
It does not. The proof is not a guarantee that the output is a single fixed value. The proof is a guarantee that the output was computed the right way given the model. Probabilities are values too. The question is whether the probability you produced is the one that follows from the specified prior, likelihood, and combination rule, or whether it is a number the model just emitted because the surrounding prose called for one.
Consider a clinical decision support system being asked if there could be a clinically significant bleeding event in the next 30 days when warfarin is co-administered with amiodarone. The right answer is not "yes" or "no." It is a probability, conditional on the patient's baseline risk factors, the interaction's known effect on the relevant pharmacokinetic pathway, and the combination rule for stacking risks.
The evaluation path here looks the same as before: a model produces an answer with some likelihood score, a stronger model grades the rationale, and you get a score. There is no way to know whether the baseline was right, whether the interaction factor was applied to the right pathway, whether the conditional independence assumption was even examined. The evaluation measures whether the answer sounds correct. It cannot inspect the computation.
The proof path tracks the computation. The baseline risk is a defined quantity sourced to a specific clinical reference, with its uncertainty interval as part of the type. The interaction factor is a defined modifier sourced to the FDA label section that establishes the pharmacokinetic mechanism. The combination rule is a theorem of the underlying probability calculus, applied to the specific patient context. The output is a probability with an interval, and the proof object certifies this is the unique value derivable from these inputs under these rules.
The proof does not eliminate uncertainty about the world. The interval is still wide because clinical biology is noisy and the evidence base is finite. What the proof eliminates is uncertainty about the computation, it makes the output as trustable as the words of the best diagnostician. You know that the right prior was used. You know that the combination rule was applied correctly. You know that no step substituted plausible-sounding prose for an actual derivation. The uncertainty that remains is the irreducible uncertainty of the domain, not the artifactual uncertainty of an LLM that may or may not have remembered the right pharmacokinetic pathway today.
This is the right generalization. Probability theory is logic. Bayes' rule is a theorem. The construction of a posterior from a prior and a likelihood is a derivation. Anywhere you have a probabilistic computation, you have a candidate for formalization. The output is a probability; the proof is about whether the probability was earned.
Evaluation vs Verification
Evaluations have clear, undeniable strengths: they measure baseline capability, detect regression across model versions, and allow us to compare different methods at scale. They are essential tools for tracking the macro-progress of a system over time. But evaluation is not verification.
The core difference is a boundary of scope and certainty:
Evaluation is a property of a sample average. It tells you that across a thousand test cases, a model is right 94% of the time. It gives you a statistical trend, but it cannot tell you if this specific output on this specific input is part of the 94% or the 6%.
Verification is a property of an individual artifact. It doesn't care about benchmarks or averages. It is a deterministic guarantee, certified by an artifact, that a small, trusted program can check with absolute certainty, right now, for the single user asking the question.
The current "trustworthy AI" discourse collapses these. It treats higher evaluation scores as if they convert smoothly into higher trust, and longer reasoning traces as if they convert smoothly into proofs. Neither conversion is real. The gap does not close with scale. It does not close with better judges. It does not close with chain-of-thought variants that look more like reasoning. It closes when you put a proof in the box.
The substrate of trust in AI systems that matter is not a number a model produces about another model's output. It is a derivation a kernel can check.
With traditional ML, an output came with a probability score, and we knew what that uncertainty meant. We built workflows around it: pick a threshold, route low-confidence cases to humans, calibrate on a held-out set, monitor for drift. The substrate of trust was a number, and we knew how to use the number.
LLMs broke that workflow. People stopped using the probabilities associated with LLM tokens and instead started relying on the final natural language output from the LLM for decision making. Probability vanished. The whole text was the output, and parts of it were meaningless without the larger context.
I remember thinking: this is not how ML is done. Who is going to trust answers where you can't even define confidence?
I was surprised by what followed. Users started treating the AI not as a rigorous statistical tool with measurable limits, but like a very smart child whose word couldn’t be taken as absolute truth. We had lost our well-defined paradigm for dealing with uncertainty, but because we were getting these smart-sounding natural language outputs, we invented our own informal, ad-hoc methods to verify things - like relying on citations.
The Illusion of the Reasoning Trace
Then reasoning models arrived. We gained a reasoning trace which replaced probability. The model shows its work. A chain of thought looks richer than a scalar between 0 and 1, and on the surface this seems like progress.
It is not.
Richness is not trustworthiness. A reasoning trace looks like evidence, and that is worse than no evidence in a specific way: a calibrated number is a thin signal you know how to use, while a confident-sounding chain of reasoning is a thick signal you do not.
Plausibility is exactly what LLMs are best at producing, whether or not it tracks truth. The trace pattern-matches to "proof" without being one. The user reads it, finds it persuasive, and updates on the persuasiveness, not on whether any step is actually licensed.
This is the failure mode that gets worse as models get better. As AI becomes dangerously good at convincing you of any idea it wants, the mental model of when to trust it breaks down. The cues you used to flag "this looks wrong!" stop firing. The cross-check returns the same hallucination the model already gave you. The reasoning trace makes the wrong answer more persuasive, not less. The longer the reasoning trace, the harder it is to check the work. Once you start relying heavily on LLMs, verifying that underlying logic becomes incredibly difficult, even for experts in the domain!
The industry's response has been to bolt evaluation onto the output: run the model, score it with a stronger model, average over a benchmark, report 90%, call it trust.
Anything where you don’t know when you fail is not trust. The judge is itself a model: it samples from a distribution, its rubric is ambiguous natural language, and it is exposed to adversarial pressure from the model it grades. Calibrate it on a labeled set, and you have merely calibrated it on the labeled set; off-distribution, it drifts in directions you cannot see. Scaling the judge shifts the curve. It does not change the shape.
A proof is a different kind of object
A proof is not a score and not a trace. It is an object. Consider Lean 4, a mathematical theorem-proving language used to formally verify software and mathematics. In Lean 4, a proof of a proposition is a term whose type is that proposition. A small checker, a few thousand lines of code small enough to audit, walks the term and confirms each step follows from the inference rules. The kernel is deterministic. It returns yes or no. The same term, checked anywhere and anytime, gets the same verdict.
This is what a reasoning trace is gesturing at and failing to be. The proof is a syntactic object in a fixed logic, checked by a kernel whose correctness you can prove once and rely on forever. The trace covers the cases it covers. A proof of "every taxpayer below the threshold owes zero" covers every such taxpayer, not 90% of a sample. The quantifier is real. The coverage is complete.
The properties this gives you are not incremental improvements over evaluation. They are categorically different.
A proof is decidable to check. The kernel terminates with a definite verdict. There is no sampling, no temperature, no judge of the judge, no regress that bottoms out at humans labeling a small set.
A proof is reproducible. The verdict does not depend on which weights you loaded or which seed you used. Two people on opposite sides of an audit can run the same kernel on the same term and converge.
A proof is universal over its domain. Not statistical generalization from a benchmark to a deployment distribution that you hope resembles the benchmark. Logical coverage by the rules of the system.
A proof is adversarially robust by construction. You cannot steer a kernel by training against it. There is no smooth gradient to climb. The kernel accepts a term or it does not, and the check is decidable.
None of these properties is something an evaluation can be made to have by improving the evaluator. They are properties of the artifact, not the process around the artifact. In other words, a machine-checked proof is the most accurate reasoning chain any answer can have.
A concrete example
A single filer with $87,400 of California taxable income asks: What do I owe in 2024?
The evaluation path: prompt a model, get $3,847.62 with a derivation, ask a stronger model to grade it, get 0.91. If both models inherited the 2023 brackets from the same Wikipedia paragraph, you have measured the consistency of their shared confusion. The evaluation passes. The taxpayer is wrong. The reasoning trace, by the way, was excellent. It cited the right statute, explained the bracket structure, and walked through the arithmetic. None of that mattered, because the bracket numbers it was working from were last year's.
The proof path: compile California RTC §17041 into a typed specification where each bracket is a definition sourced verbatim from the statute. Apply the function to the input. Out comes the true value and a concrete proof object theorem true_tax_owed : tax_2024_single 87400 = 4670.56 := Eq.refl 4670.56 constructed by unfolding the definitions. The kernel checks it in milliseconds.
If someone disputes the answer, they do not dispute it with vibes. They point to a step. "This rule is misapplied." "This definition does not match the statute." Both are decidable claims. Both can be re-checked. Both terminate.
That is a different kind of artifact from "a model thinks another model got it right." It survives an auditor. It survives a regulator asking how you arrived at the conclusion. It survives litigation, where "our LLM agreed with a judge LLM" is not an answer that holds.
What about probabilistic events?
The above example is deterministic. The statute computes the answer with certainty. But many domains are not amenable to this. Clinical risk involves reasoning under uncertainty. Statistical inference produces a posterior, not a number. Drug interaction severity is a distribution over outcomes, not a verdict. Does the proof story collapse outside the deterministic case?
It does not. The proof is not a guarantee that the output is a single fixed value. The proof is a guarantee that the output was computed the right way given the model. Probabilities are values too. The question is whether the probability you produced is the one that follows from the specified prior, likelihood, and combination rule, or whether it is a number the model just emitted because the surrounding prose called for one.
Consider a clinical decision support system being asked if there could be a clinically significant bleeding event in the next 30 days when warfarin is co-administered with amiodarone. The right answer is not "yes" or "no." It is a probability, conditional on the patient's baseline risk factors, the interaction's known effect on the relevant pharmacokinetic pathway, and the combination rule for stacking risks.
The evaluation path here looks the same as before: a model produces an answer with some likelihood score, a stronger model grades the rationale, and you get a score. There is no way to know whether the baseline was right, whether the interaction factor was applied to the right pathway, whether the conditional independence assumption was even examined. The evaluation measures whether the answer sounds correct. It cannot inspect the computation.
The proof path tracks the computation. The baseline risk is a defined quantity sourced to a specific clinical reference, with its uncertainty interval as part of the type. The interaction factor is a defined modifier sourced to the FDA label section that establishes the pharmacokinetic mechanism. The combination rule is a theorem of the underlying probability calculus, applied to the specific patient context. The output is a probability with an interval, and the proof object certifies this is the unique value derivable from these inputs under these rules.
The proof does not eliminate uncertainty about the world. The interval is still wide because clinical biology is noisy and the evidence base is finite. What the proof eliminates is uncertainty about the computation, it makes the output as trustable as the words of the best diagnostician. You know that the right prior was used. You know that the combination rule was applied correctly. You know that no step substituted plausible-sounding prose for an actual derivation. The uncertainty that remains is the irreducible uncertainty of the domain, not the artifactual uncertainty of an LLM that may or may not have remembered the right pharmacokinetic pathway today.
This is the right generalization. Probability theory is logic. Bayes' rule is a theorem. The construction of a posterior from a prior and a likelihood is a derivation. Anywhere you have a probabilistic computation, you have a candidate for formalization. The output is a probability; the proof is about whether the probability was earned.
Evaluation vs Verification
Evaluations have clear, undeniable strengths: they measure baseline capability, detect regression across model versions, and allow us to compare different methods at scale. They are essential tools for tracking the macro-progress of a system over time. But evaluation is not verification.
The core difference is a boundary of scope and certainty:
Evaluation is a property of a sample average. It tells you that across a thousand test cases, a model is right 94% of the time. It gives you a statistical trend, but it cannot tell you if this specific output on this specific input is part of the 94% or the 6%.
Verification is a property of an individual artifact. It doesn't care about benchmarks or averages. It is a deterministic guarantee, certified by an artifact, that a small, trusted program can check with absolute certainty, right now, for the single user asking the question.
The current "trustworthy AI" discourse collapses these. It treats higher evaluation scores as if they convert smoothly into higher trust, and longer reasoning traces as if they convert smoothly into proofs. Neither conversion is real. The gap does not close with scale. It does not close with better judges. It does not close with chain-of-thought variants that look more like reasoning. It closes when you put a proof in the box.
The substrate of trust in AI systems that matter is not a number a model produces about another model's output. It is a derivation a kernel can check.