11
Mins
Foundations
Verified AI
The Age of Everyday Provers
Why the next frontier of formal reasoning is not just proving math theorems, but verifying everyday claims in software, law, tax, medicine, and compliance.

A lot of recent excitement around AI-assisted formal reasoning has centered on proving difficult mathematical statements, with recent work even solving problems that were previously open. However, an equally important and far larger set of applications lies in the verification of real-world claims and decisions. Examples include determining whether a diagnosis follows from a patient's clinical record, whether a taxpayer satisfies statutory eligibility criteria for a deduction, whether a cryptographic protocol guarantees confidentiality or whether a software system satisfies its specification. Because such judgments often carry significant operational consequences, they demand strong guarantees of correctness.
In such settings, the objective is not merely to find a proof eventually, but to produce one reliably and within practical time constraints. It is tempting to assume that a large model, once good enough at proving for mathematics, will simply generalize across all of these domains. Expecting a math-optimized search strategy to generalize to everyday logic fails for two reasons: the scarcity of formal verification data, and the fundamental structure of the search problem itself.
A model generalizes only as far as what it has seen, and mathematics is one of the most thoroughly documented forms of reasoning — millions of solved problems, proofs, textbooks, lectures, and discussions are publicly available. Software verification is a far more specialized activity, with substantially fewer examples and practitioners; in fact, many software engineers are unaware that program correctness can be formally proved at all. Formal legal reasoning is rarer still, with few examples in public datasets and virtually no presence in practical use outside of academic research. As domains become more specialized, both the volume of available training data and the community producing it shrink, so the generalization we observe in mathematics cannot be assumed to carry over.
The second is the structure of the proof search itself, and this will be the focus of this blog. In mathematics, finding a proof often hinges on a creative leap and there is no general procedure that guarantees the model will find it. We are essentially betting on the model to explore the right path, and it may or may not do so, which makes both how quickly a proof is found and whether one is found at all hard to guarantee.
In domains like software verification and regulatory compliance, by contrast, the difficulty often comes from the sheer number of constraints involved. A claim may depend on thousands of interacting rules and laws. Some of the reasoning in these settings can be delegated to symbolic solvers (such as SMT solvers), which systematically explore the space of possibilities and discharge cases. This makes it possible to generate consistent proofs in a mechanized way, although in practice these solvers can become computationally expensive and may consume impractical amounts of time and resources when applied naively.
Together, this points to a conclusion that challenges a common assumption in AI-assisted formal reasoning: that there exists a single universally optimal prover waiting to be built. Different domains present fundamentally different requirements and challenges. The structure of the rules, resource constraints, and the size of the search space can vary dramatically, with important implications for how provers should be designed. In this blog, we examine how the expected structure of proofs varies across domains and the implications this has on proof search.
Proving as Search for a Tree
Proving is essentially a tree search problem. The statement you want to prove sits at the root. Each branch is a reasoning step — applying a rule, splitting into cases, invoking a known result — producing sub-statements simpler than what came before. The leaves are where you bottom out: either something trivially true, or a case that's clearly impossible.
Here is a clean example of this:
Claim: There are infinitely many primes.
Proof:
assume that there are finitely many primes p₁ , p₂ , ... , pₙ
construct a new number N = (p₁ × p₂ × ... × pₙ) + 1,
split into two cases:
N is prime, or
N has a prime factor q.
Both branches lead to a contradiction, and the proof terminates.
Here is the same proof represented as a tree:
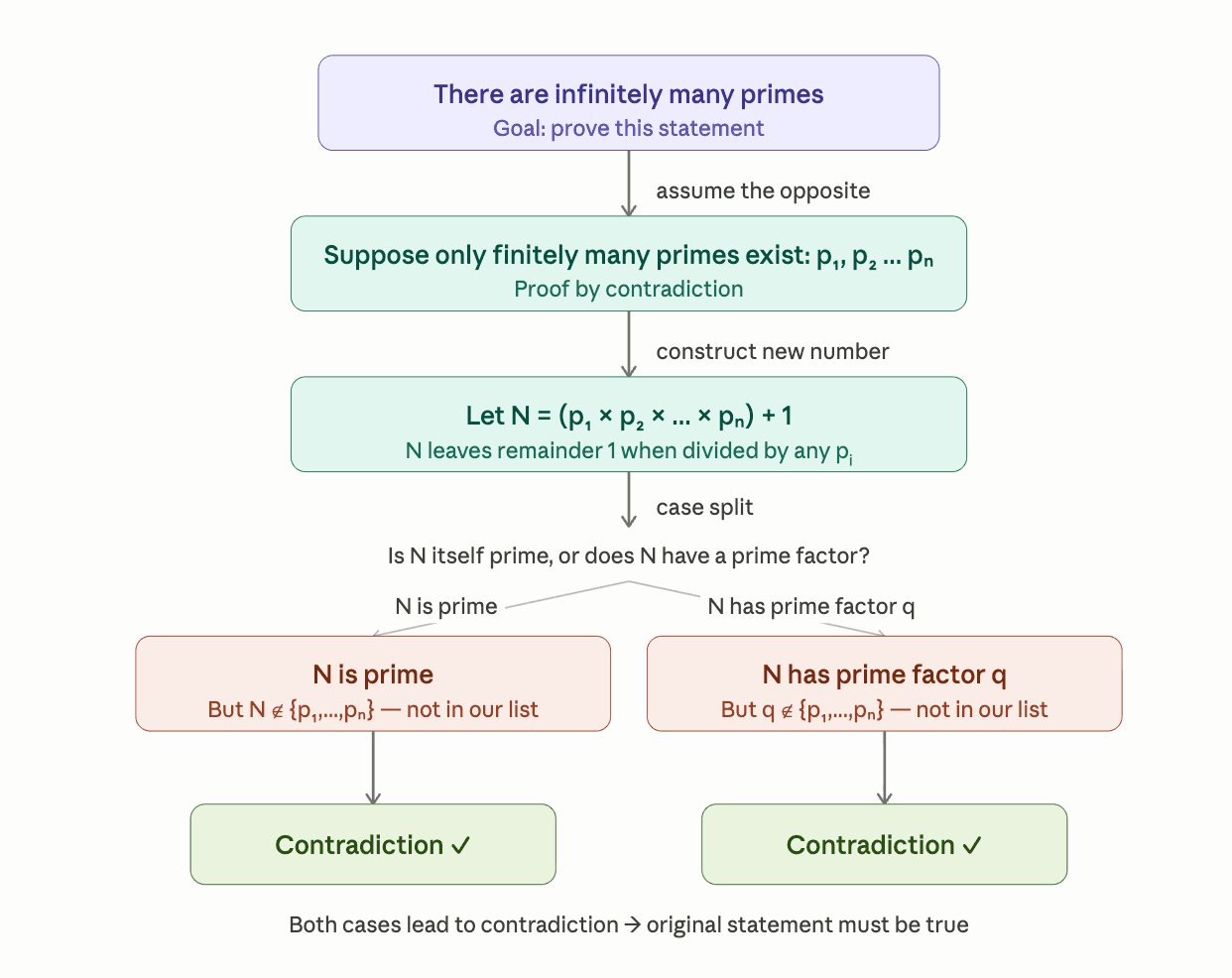
A prover's job is to find a valid path from root to leaf.
The difficulty is that at every node there are many viable paths forward, and most are dead ends or restrictively convoluted.
Here is an example:
Claim: n² − n is always even.
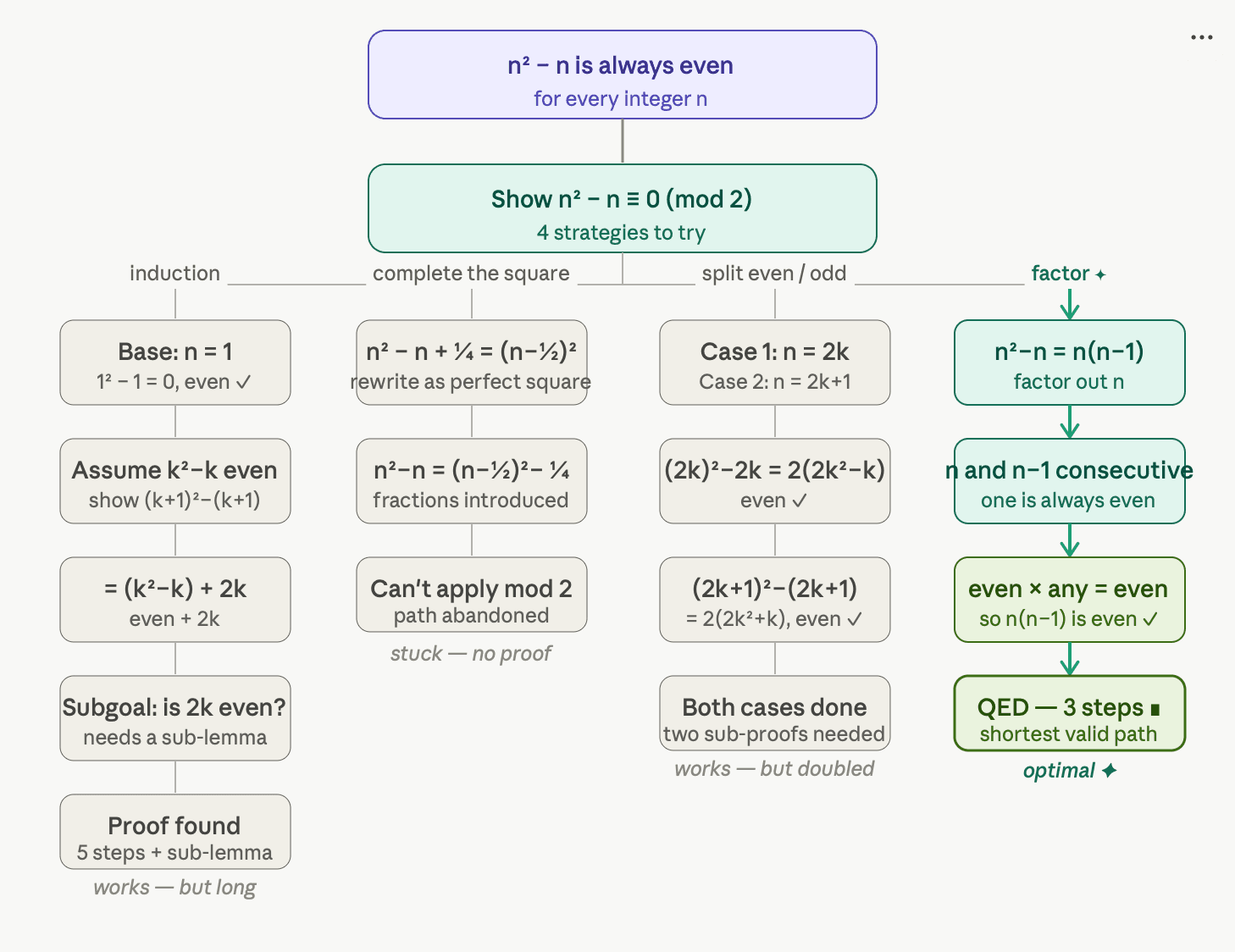
All four approaches shown above are valid things to try — induction and case-splitting even produce correct proofs. What a smart prover needs to recognize is that factoring introduces a structural property, consecutiveness, that connects directly to the goal.
A good prover needs to be fast and principled about which branches to explore, and as we'll see, that strategy depends on the expected shape of the proof tree.
The Spectrum of Reasoning Trees
Think of proof trees as sitting on a spectrum defined by two dimensions: how deep the reasoning needs to go, and how broad the branching is expected to be. At one end: deep, but narrow trees, where the statement must be broken down into a chain of simpler statements, but you rarely need to split into many cases. At the other: wide, but shallow trees that do not require extensive chaining but require lots of case splitting.
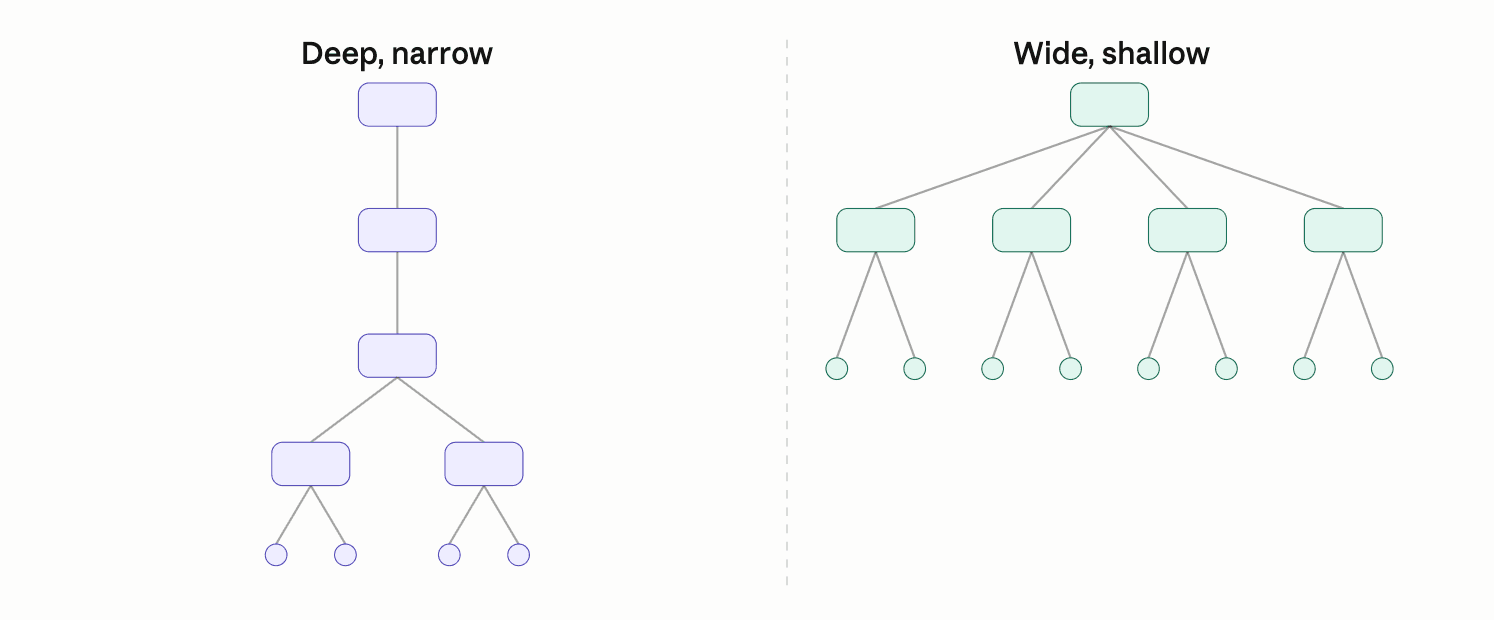
Deep and Narrow: Mathematical Proving
In mathematics, arguing via tons of cases — brute force — is considered inelegant. A mathematician aims to find clever reductions that eventually collapse the problem into something already known. The tree is tall because each reduction takes work to justify, but it stays narrow.
Example: Wiles' proof of Fermat's Last Theorem chains three deep reductions: Frey showed a hypothetical solution would produce an elliptic curve with anomalous properties; Ribet proved such a curve cannot be modular; Wiles proved all semistable elliptic curves are modular, contradiction. Each link took years of creativity to establish.
An automated proving system for mathematics must have the creativity to come up with effective reductions by applying known lemmas. The time spent and resources consumed by this search process are often of secondary importance. Because mathematical proofs are typically judged by their existence and correctness rather than the time required to discover them.
Moderately Deep and Broad: Software Verification
Move along the spectrum and you reach software verification: proving that a program adheres to its specification. The proof tree expands in both dimensions simultaneously.
The breadth comes from control flow: if-else branching, bounds check, and pointer dereference all force a case split. Unlike mathematics, the case splits cannot be avoided by a clever reduction: they are structural, forced by the program.
Depth comes from how the program state evolves over time. For instance loop iterations produce a new state whose correctness depends on the previous one, creating a chain of dependent proof obligations. In principle, one could try to reason about every iteration separately, but loops may execute an unbounded number of times. Instead of unrolling an arbitrarily long chain of states, verification introduces invariants: properties that are preserved by each iteration.
This introduces both depth and breadth to the proof tree:
Finding the invariants is the depth, classically a human contribution
Proving the invariants is the breadth, classically done with the help of numerical solvers (such as an SMT solver).
An automated prover for this domain therefore needs both halves: the creativity to find an invariant (the depth), and the case-work to prove it (the breadth). The resources consumed by this search process are no longer secondary. The goal of software verification is to integrate into engineering workflows to check for vulnerabilities. Here, proofs must be generated reliably and within practical time budgets. As a result, the objective is not merely to find a proof, but to find one consistently and efficiently.
Broad and Shallow: Regulatory and Legal Domains
At the far end of the spectrum are domains like tax law, employment regulation, and contract compliance. These domains contain tens of thousands of rules: statutes, thresholds, definitions, exceptions, and cross-references that interact with each other. A proof must work through every rule case relevant to the statement, but discharging each case is usually a simple calculation. The proof tree ends up very wide (many cases) and relatively shallow (each case is a simple calculation).
Example: Sam, age 45, withdrew $10,000 from his Traditional 401(k) to pay medical bills that exceed 7.5% of his Annual gross income. How is this withdrawal taxed?
The tax treatment depends on two questions, asked in order. First, what type of account does the money come from? Second, what circumstance triggered the withdrawal? Each question has multiple possible answers, and each answer carries its own set of follow-on rules.

At the first level, the prover identifies the account type. Sam's account is a Traditional 401(k), so the other four account types are ruled out. Each of those branches has its own ruleset that never needs to get unfolded.
At the second level, under Traditional 401(k), the prover identifies the distribution circumstance. Sam is 45, but his withdrawal qualifies for the medical-expense exception. The other four circumstances — normal age 59.5+ withdrawal, early without exception, RMD, rollover, never get expanded.
An automated prover for this domain must be resource and time efficient, but must also navigate two additional constraints:
1. The rules are dynamic
Mathematical theorems do not change. Once a result has been proved, a prover can safely memorize and reuse it indefinitely. In fact, much of the success of modern provers comes from training on large libraries of previously established results. On the other hand, tax codes and employment regulations are amended frequently, and a result that was valid under one version of the rules may become false under the next. Therefore, a prover in these domains must remain agnostic to the specific rules it encountered during training and instead reason over the live rule set at inference time.
2. The branching coefficient
The second bottleneck is the high amount of case-splits involved in the proof that prevents the naive use of symbolic solvers. A single statement may depend on hundreds of rules, and each of those can depend on hundreds more. Every individual rule may be a simple calculation, but fully unfolding all of them produces a search space far too large to explore (causes symbolic solvers to timeout).
The key observation is that most of those branches never need to be explored and the logical structure of the goal tells the prover which ones.
When a goal is a conjunction — several conditions that must all hold — a single failed condition makes the goal false, and everything else becomes irrelevant. The right move is to prune: test the cheap, decisive condition first and skip the expensive branches entirely.
When a goal is a disjunction — several conditions where any one holding is enough — a single satisfied condition makes the whole goal true. The right move is to commit: pick one promising branch and compute it through to the end, rather than fanning out and partially exploring all the alternatives.
An efficient prover in this domain reads the structure of the goal and decides whether to prune or to commit.
Example: Consider proving that a taxpayer with taxable income of $10,000 does not fall in a particular tax bracket. The bracket check has two conditions that must both hold (conjunction): the taxpayer must meet certain eligibility criteria, and their taxable income must fall between $36,900 and $89,150. Since both must be true, if either fails the answer is immediately false.
Given that taxable income is $10,000, the income condition fails immediately — $10,000 does not lie in that range. The eligibility condition is now irrelevant: it does not matter whether the taxpayer qualifies or not, the bracket check is false regardless.
If we unfold the eligibility criterion, the rule graph spans 150+ nodes across seven sections of the tax code. A solver would take exorbitant amounts of time to discharge each case, slowing it down significantly.

A naive prover times out on problems like these because it expands branches blindly.
The Right Tool for the Right Tree
The proof search problem changes shape from domain to domain, and hence the optimal architecture of the prover has to change with it. Depth, breadth, and rule stability determine what kind of search can succeed, and therefore what kind of system you have to build.
Proving has long been treated as a purely mathematical endeavor, but the need for verifiable truth extends far beyond the whiteboard. Wherever a rule set can be made precise, a software specification, a tax code, a corporate policy, or a legal contract, a formal proof is possible.
However, as we have seen, the shape of the proof search changes dramatically from domain to domain. You cannot use a deep, narrow mathematical search strategy to navigate the broad, dynamic, and shallow trees of regulatory compliance. The optimal architecture must adapt to the constraints of the environment.
Today, Large Language Models have made generating answers abundant, but verifying those answers remains largely manual, expensive, and error-prone. Predictions require scrutiny; proofs provide guarantees. We need purpose-built architectures designed to navigate the specific reasoning trees of the real world.
That is the future we are building at Pramaana: creating specialized, highly efficient provers that turn the critical judgments organizations make every day into verifiable truths you can trust without a second thought.